The six-step model is a generalised process cycle for security incident response. The best tip for success is being prepared.
Proper and advanced planning ensures that all response procedures are known, coordinated and systematically carried out. It also facilitates management in making appropriate and effective decisions when tackling security incidents, and in turn minimises any possible damage. The plan includes strengthening security protection, taking an appropriate response to address the incident, recovery of the system and other follow up activities.
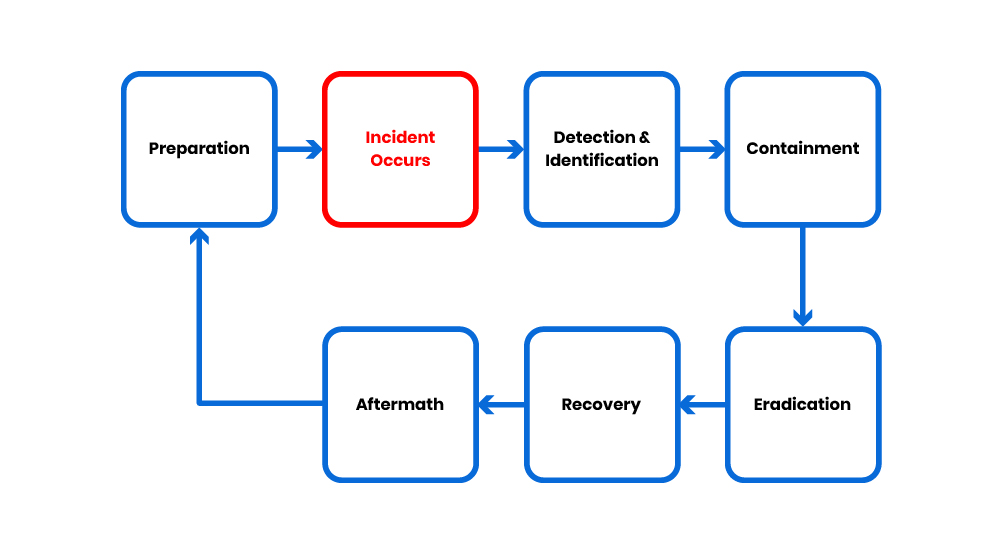
Preparation
Planning allows a top down approach to incident response management to provide an assurance of quality and response time.
Determine the local policies.
Make sure the incident response strategy is consistent with the company security policy and sufficient authority is granted to the incident response team to take specified actions, e.g. switch off company web services in the critical moment.
Define roles and responsibilities of incident response team and parties participating in the security incident handling process.
Define the roles and responsibilities of other company staffs. Communicate this to functional management.
Establish the list of prioritised information asset / services and acceptable downtime.
Develop Reporting Procedure, Escalation Procedure and Security Incident Response Procedure. These procedures should be communicated to all employees, including management personnel, for their reference and compliance.
Facilitate early detection, e.g. by building a simple technical environment sufficient for job function and a user-friendly help desk.
Develop and maintain good backup strategy.
Develop and maintain the Call List.
Update with guideline, checklist and tools of HKCERT and other CERT centers.
Develop knowledge and skills of incident response team by training and sharing.
Provide adequate staff training to ensure all concerned staff and management are capable of handling security incidents.
Educate users the emergency procedure and incident reporting contacts.
Set up system time synchronisation mechanisms for computer systems.
Set up monitoring and alerting mechanism for computer systems, such as install intrusion detection system, anti-malware and content filtering tools, enable system & network audit logging and perform periodic security checking using security scanning tools.
Detection and Identification
Monitor abnormal events, e.g. error messages, suspicious events in logs, poor performance and unusual capacity growth.
Determine type of problem and extent of impact.
Start taking record using a standard incident logging form.
Handle information with reference to the guideline on evidence collection.
Make a full backup of compromised system as soon as you find it a real incident and store it in secure place.
Capture records of incidents, e.g. auditing log, accounting log, etc.
Inform the management and other "Right" people using the call list (IRT, ISP, network service provider…) and call tree (system owner notification). Enforce the "Need to Know" policy and use secure out-of-band communication channel when necessary.
Containment
Activities in this stage may include:
Conducting impact assessment of the incident on data and information of the system to confirm if the concerned data or information had already been damaged by or infected in the incident;
Protecting sensitive or critical information and system. For instance, move the critical information to other media (or other systems) which are separated from the compromised system or network;
Deciding on the operation status of the compromised system;
Building an image of the compromised system for investigation purpose and as evidence for subsequent follow up action;
Keeping a record of all actions taken during this stage; and
Checking any systems associated with the compromised system through shared network-based services or through any trusting relationship.
One of the important decisions to be made is whether to continue or suspend the operation and service of the compromised system. This will very much depend on the type and severity of the incident, the system requirement and the impact on the image of the company, as well as the predefined goals and priorities in the incident handling plan of the system.
Actions to be taken may include:
Shutting down or isolating the compromised host or system temporarily to prevent further damage to other interconnected systems, in particular for incidents that will spread rapidly, for machines with sensitive information, or to prevent the compromised system from being used to launch attack on other connected systems;
Stopping operation of the compromised server;
Disabling some of the system's functions;
Removing user access or login to the system;
Continuing the operation to collect evidence for the incident. This may only be applied to non mission-critical system that could accept some risks in service interruption or data damage, and it must be handled with extreme care and under close monitoring.
Protect computer evidence by moving people out of reach of computer, electric switches, storage media and telephone
Assess the risk of continuing operation and if the downtime might exceed the acceptable level. Management should make the decision based on the recommendation of the IRT on whether the activation to disaster recovery site if necessary.
Keep system owner informed of the status to get their trust and make them feel comfortable.
Eradication
The goal of eradication is to eliminate or mitigate the cause of the security incident. During this stage, the following actions may need to be performed depending on the type and nature of the incidents as well as the system requirement:
Stop or kill all active processes of the attacker to force the attacker out.
Delete all the fake files created by the attacker. System operators may need also to archive the fake files before deleting to aid case investigation.
Eliminate all the backdoors and malicious programs installed by the attacker.
Apply patches and fixes to vulnerabilities found on all operating systems, server and network devices etc. Patches or fixes applied should also be tested thoroughly before the system is restored to normal operation.
Correct any improper settings in the system and network e.g. mis-configuration in firewall and router.
In case of a malware infection incident, inoculate the malware from all infected systems and media following anti-malware software vendor advisories.
Provide assurance that the backups are also clean to prevent the system from being re-infected at a later stage when system recovery from backup is needed.
Make use of some other security tools to aid in the eradication process, for instance, security scanning tools to detect any intrusion, and apply the recommended solution. These tools should be kept up-to-date with the latest intrusion patterns.
Update the access passwords of all login accounts that may have been accessed by the attacker.
In some cases, the supporting staff may need to reformat all the infected media and reinstall the system and data from backup, especially when they are not certain about the extent of the damage in a critical system or it is difficult to completely clean up the system.
Recovery
The purpose of this stage is to restore the system to its normal operation. Examples of tasks include:
Perform damage assessment.
Re-install the deleted / damaged files or the whole system, whenever required, from the trusted source.
Bring up function / service by stages, in a controlled manner, and in order of demand, e.g. the most essential services or those serving the majority may resume first.
Verify that the restoring operation was successful and the system is back to its normal operation.
Prior notification to all related parties on resumption of system operation, e.g. operators, administrators, senior management, and other parties involved in the escalation procedure.
Disable unnecessary services.
Keep a record of all actions performed.
Aftermath
The goal of Aftermath is to learn from the lesson of the incident. The Aftermath should start as soon as possible after the incidents. Management, users and the on-site IRT should be involved.
A post mortem analysis should be conducted to find out areas of improvement, for example:
Checking if the current configuration and procedure are sufficient.
Checking if more user education is required.
Determining if an external security audit is required.
Determining if the incident should require any legal action.
All parties involved should be invited to give comment to the draft of the post mortem analysis.
An executive summary with recommendations for improvement should be sent to management.
The management should assess the report and select the recommendations for improvement to be implemented. Those who report incidents and those who helped to make the incident response successful should be acknowledged or rewarded.
The next step of Aftermath is going back to the first step "Preparation" for implementation of selected recommendations and starts another cycle of continuous improvement.